
Утилита обслуживания наборов данных (Data Set)
Утилита обслуживания наборов данных (3.2, Data Set) ориентирована на обработку как последовательных, так и библиотечных наборов данных и доступна из меню утилит. С ее помощью выполняются операции переименования, удаления, каталогизации и исключения из каталога наборов данных, просмотр служебной информации о наборе данных и т.д. Только эта утилита позволяет создавать (распределять) новые наборы данных.
В панели утилиты DataSet (рис. 5.46) пользователь должен определить имя обрабатываемого набора данных одним из ранее рассмотренных способов, а затем выбрать операцию обработки, введя ее код в поле Option и нажав клавишу ВВОД.
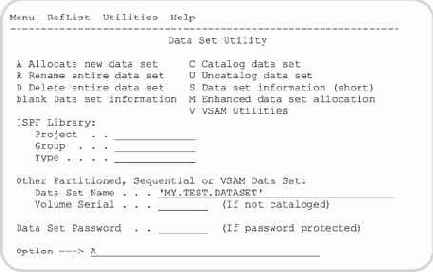
Рис. 5.46. Панель утилиты обслуживания наборов данных
Функции утилиты представлены в верхней части панели и включают:
- A - создать (распределить) новый набор данных;
- R - переименовать набор данных;
- D - удалить набор данных;
- blank (пробел) - отобразить полную информацию о наборе данных;
- C - каталогизировать набор данных;
- U - исключить набор данных из каталога;
- S - отобразить краткую информацию о наборе данных;
- M - создать (распределить) новый набор данных с использованием SMS-технологии (требует специально сконфигурированного тома);
- V - работа с наборами данных типа VSAM.
Ниже будет рассмотрена только одна, но очень важная функция - распределение нового набора данных. Почти все остальные функции (кроме M и V) могут быть выполнены с помощью утилиты Dslist.
Для распределения нового набора данных пользователю необходимо задать его имя, затем ввести команду А в поле Option и нажать клавишу ВВОД. После этого на экране появится панель Allocate New Data Set, с помощью которой можно установить все необходимые параметры создаваемого набора (рис. 5.47).
При создании стандартного последовательного или библиотечного набора данных (без использования SMS технологии) обязательными для ввода являются следующие параметры:
Space units - единицы измерения предоставляемой памяти;
Primary Quantity - объем первично выделяемого пространства памяти в заданных единицах;
Secondary Quantity - объем дополнительно выделяемого пространства памяти в заданных единицах (используется в случае нехватки первично выделенной памяти);
Directory blocks - количество блоков (по 256 КB каждый), резервируемых под оглавление (только для библиотечных наборов данных);
Record format - формат логических записей;
Record length - длина логической записи;
Block size - размер блока.
Представленные на рис. 5.47 значения соответствуют созданию библиотечного набора данных с параметрами, определяемыми следующим оператором DD:
//ХХХХ DD SPACE=(6160,(96,12,10)),RECFM=FB, // BLKSIZE=6160,LRECL=80
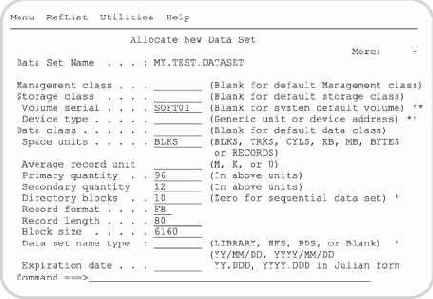
Рис. 5.47. Панель распределения нового набора данных
Следует отметить, что количество блоков оглавления библиотечного набора данных выбирается с учетом следующей информации:
- наборы данных, использующие статистику разделов, позволяют создавать по шесть разделов на каждый блок;
- наборы данных, не использующие статистику разделов, позволяют создавать по 21 разделу на каждый блок;
- библиотеки загрузочных модулей, позволяют создавать от четырех до семи разделов на каждый блок в зависимости от атрибутов.
Для создания библиотечного набора данных типа PDSE необходимо дополнительно ввести значение Library в поле Data set name type. Для создания последовательного набора данных поле Directory blocks необходимо оставить пустым.
После ввода всех необходимых параметров следует нажать клавишу ВВОД. На экране вновь появляется основная панель утилиты DataSet. При успешном выполнении функции будет сформировано короткое сообщение "Data set allocated", означающее, что набор данных создан. В противном случае будет выдано сообщение об ошибке, и пользователь должен проверить правильность введенных параметров, повторив все указанные действия.